
Looking for our free text analysis tool? It's moved!
Online SEO Analysis Tool
Unlock your site's potential using our in-depth SEO Analysis
No matter your level of SEO prowess, it's inevitable that on every site there are opportunities to improve your organic search traffic, and we're to help you do it.
By combining your search console data with our own SEO crawler that analyzes your content and compares it against your SEO results we can deliver unique insights into how to deliver compounding gains for your site or clients.
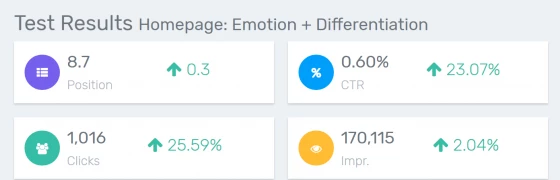
Advanced SEO Testing Tools
Test Every Change You Make To Your Site, From Content To Titles
Use our SEO testing suite to analyze the impact of every change you make on the site. Whether you want to test new titles and meta descriptions for better CTR or long tail traffic, or make fundamental changes to the content of your page, our JS testing system allows you to implement changes on your clients site without bothering developers.
Testing multiple changes is a breeze too, using our templating system. Quickly try a new pattern across 1000s of location or product pages and analyze the impact before rolling them out to production.
For each test we offer an analysis of core metrics such as your average position, change in clicks or even the total number of keywords you rank for, then allow you to drill down into detail to see the keywords and modifiers that moved.
Automated Change Tracking
Already confident your changes will be positive? Then dive in and update your sites - we'll monitor for every change you make, and report back on the impact, whether positive or negative. Show your clients the value you've delivered, with an comprehensive report on the work you've done to a site, and the gains you've had.
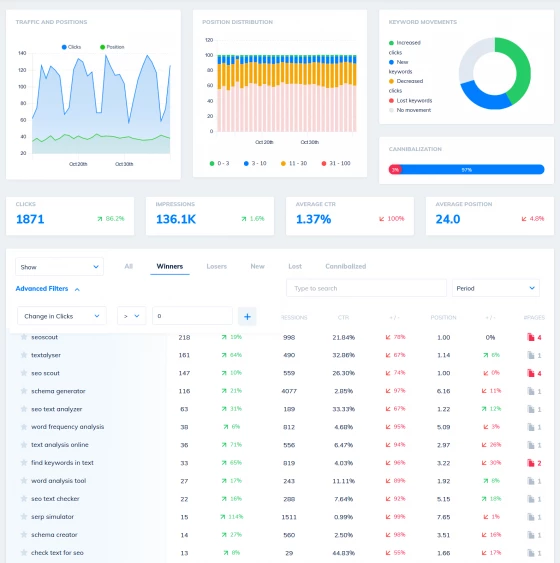
Unlimited Keyword Rank Tracking + Google SERP Position Analysis
Don't let your rank tracker limit your understanding
Dig deep into your search console data, as we draw insights from every keyword your site appears for, not just the handful of keywords you threw in a rank tracker 6 months ago. Ignore the noise of individual keywords yo-yoing due to proxies, personalization and SERP testing, and start tracking the performance of every keyword under the sun.
See which long tail modifiers are driving the most traffic. Discover low hanging fruit such as page two positions you could claim with a little love, or the keyword modifiers you almost rank for that are missing from your title and heading tags.
Use our insights to update your content and claim new positions overnight.
Analyze your queries for terms that are low in clickthrough rate then optimize your titles with an SEO test to steal eyeballs away from competing listings.
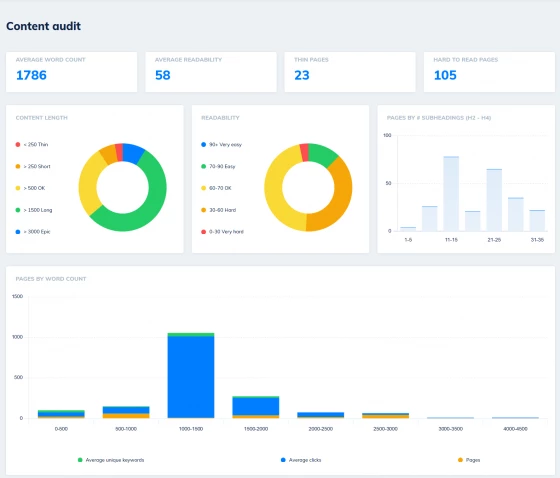
Content + Technical SEO Audits and Issue Tracking
Uncover the technical and content issues holding your site back
Let SEO Scout show you exactly which issues are holding your site back from better performance. We won't hit you with 100 action items, but focus on the priority issues where a fix can move the needle overnight. From thin content to slow pages, poor internal link structure to missing or weak title tags, we'll help you discover - and fix - your site's weak points to help lift you higher in the SERPs
Internal link analysis and opportunities
Build your topical relevance with strategic internal linking
One of our most powerful tools when optimizing a page is effective internal linking. Quickly analyze your site's internal link structure and find pages with low or no internal links - or pages with no links from within article content. Analyze the incoming anchor text from your internal links, and increase the diversity to signal to Google your relevance for a wider range of long tail keywords.
Use our Internal Link opportunity tool to find the most relevant pages on your site that don't already link to your target page, then add a new link with optimal anchor text to see powerful gains in your search performance.
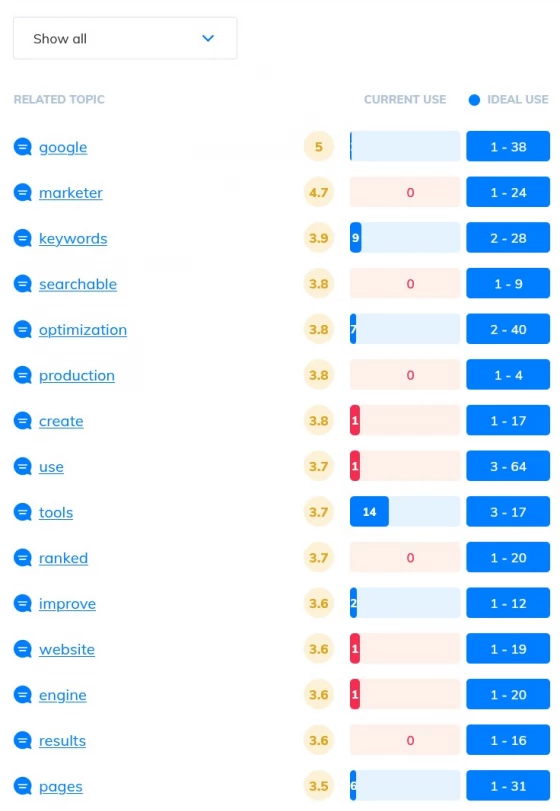
Content Analysis Tools
Content optimization using topic research
Use AI to write high quality content that Google loves
Let SEO Scout show you exactly what your article needs to rank. Our topic research tools perform a topical analysis of your competitor's articles to discover the most relevant entities, topics and terms they are writing about.
Our content grader then analyzes your own copy, pointing out the missing entities that you can use to add depth to your content, increasing the comprehensiveness and raising your content quality.
Content opportunities and FAQ ideas
Discover content and questions your customers are searching for
Dig deep into your own search data to find the queries Google wants to show your site for that you don't yet target with your content.
Our content opportunities tool will highlight the high impression keywords you are ranking for yet not specifically targeting in your existing page titles. It's a simple job to write a more relevant page for the query and instantly claim higher rankings.
Your search console data also holds a wealth of knowlege about the questions your customers are asking. By checking your keyword position for 'question' words we can quickly highlight the FAQs you rank on page 2 or higher for without trying. Just knock out a quick how to or Q&A page and you could catapult your site onto page 1
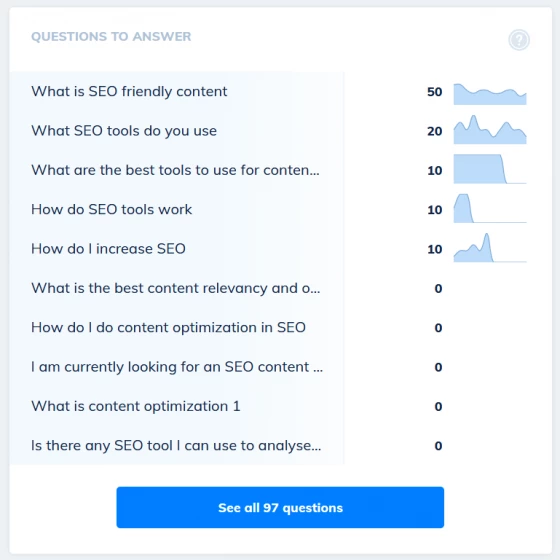
Find 'Missing Keyword' Analysis and Insights
Uncover the keywords you've missed and boost your long tail rankings
As SEOs we know a searcher might use an entire dictionary of synonyms to find our site - but our writers often don't!
SEO Scout automatically compares the content on every page of your site to the actual keywords you rank for, highlighting opportunities to soar higher in the SERPs using simple tweaks to your page titles, headings and copy.
We make it easy to identify the most valuable synonyms and modifiers your customers are searching for that you don't target yet - all you need to do is update your page to see an immediate impact on your results.
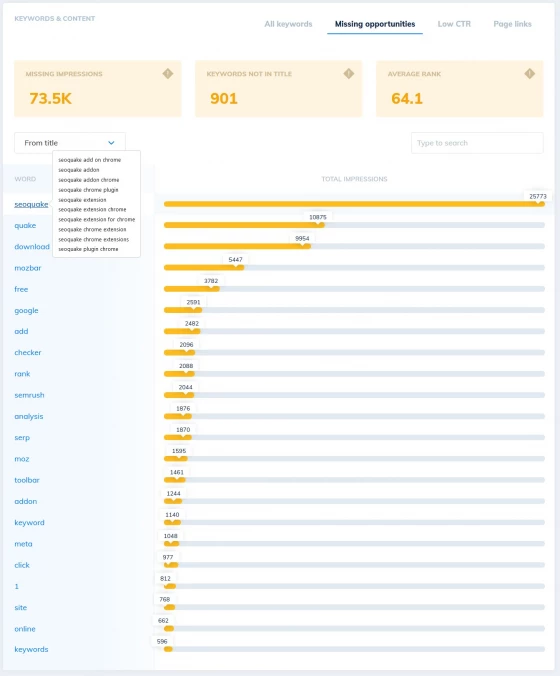
Keyword Analysis Software
Analyze Your Site's Keyword Ranking Performance
Find personalized keyword opportunities and track your growth
Dig deep into your current keyword rankings and look for the opportunities there. From the "near miss" keywords in striking distance of page one - but with tons of potential - to the ones low in CTR, you can discover trends in your keyword data in just a couple of clicks.
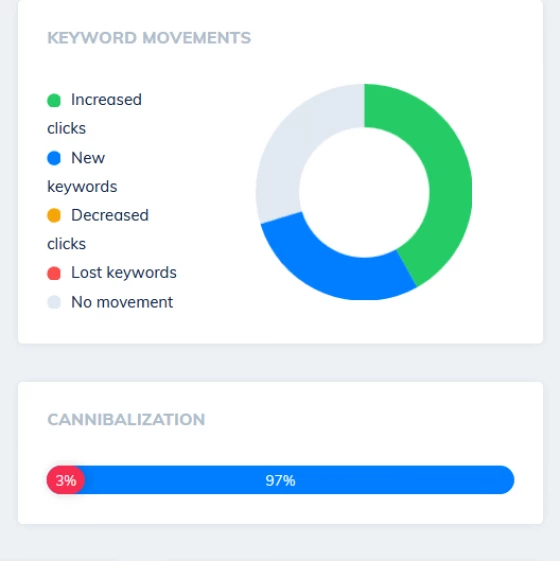
Keep tabs on which keywords are winning search visibility, and which are dropping away by comparing your search performance over time
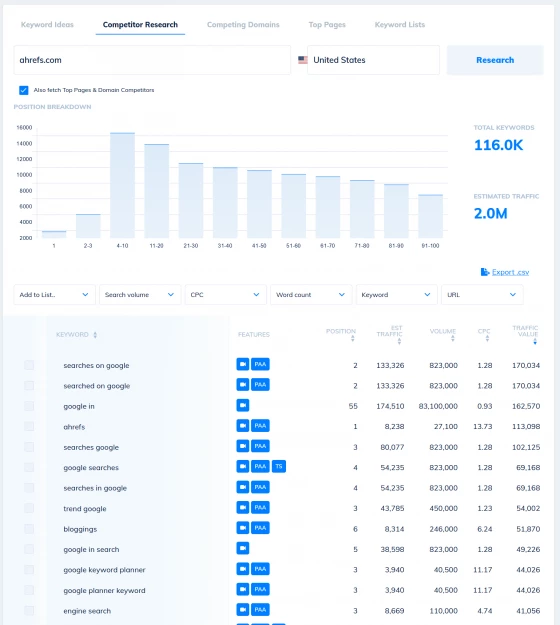
Competitor Keyword Analysis Tools
Spy on your competition's best keywords
Want to understand which keywords are sending your competitors their traffic? How about learning which pages on their domain perform the best, and the entire range of their long tail rankings?
Our competitor analysis tools make it simple to discover a ton of new content ideas in minutes, simply by exploring your competitor's most profitable keywords.
Prevent Keyword Cannibalization
Avoid Keyword Cannibalization + Stop Competing With Yourself
Stop your site competing with itself by diagnosing cases of keyword cannibalization. We track every URL and keyword on your site, and make it easy to filter to keywords that are showing multiple pages for a query.
Help Google understand which pages on your site to rank top for a specific query by consolidating content, deoptimizing problematic pages and increasing internal linking to make it clear which URL deserves to rank.
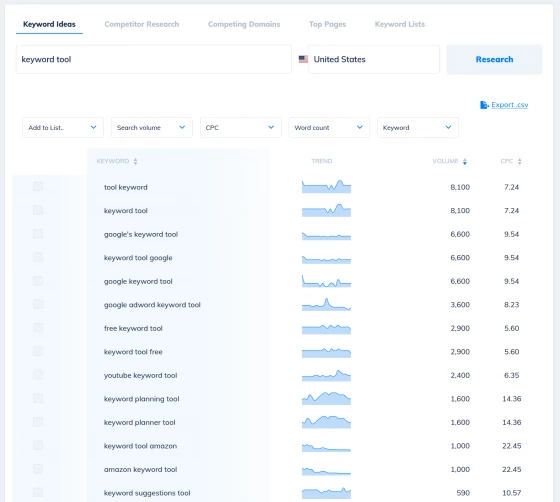
Discover new keyword ideas and opportunities
Generate 1000s of keyword suggestions using our Keyword Finder
Need some inspiration for your next content piece? Our keyword research tools help you uncover some of the best keywords for your blog post or article.
Filter 1000s of keywords by volume and CPC, then build your own list of keyword ideas ready to turn into a content brief for your writing team.
Go beyond keyword research. Use Natural Language Processing to analyze the top 30 Google results for your keyword
Edit your content using our assistant & ensure your article covers all the entities and topics Google expects you to include.
Discover the questions your customers ask, with over 200 FAQs pulled from People Also Ask, Quora and Google Suggest
Edit your content using our assistant & ensure your article covers all the entities and topics Google expects you to include.
Discover the questions your customers ask, with over 200 FAQs pulled from People Also Ask, Quora and Google Suggest
